刚刚!OpenAI回滚了最新版本的GPT-4o,因ChatGPT「过于谄媚」
刚刚!OpenAI回滚了最新版本的GPT-4o,因ChatGPT「过于谄媚」昨晚,奥特曼在 X 上发了条帖子,大意是由于发现 GPT-4o 「过于谄媚」的问题,所以从周一晚上开始回滚 GPT-4o 的最新更新。
来自主题: AI资讯
8823 点击 2025-04-30 16:44
 搜索
搜索
昨晚,奥特曼在 X 上发了条帖子,大意是由于发现 GPT-4o 「过于谄媚」的问题,所以从周一晚上开始回滚 GPT-4o 的最新更新。

坏了,AI 当「舔狗」这件事藏不住了。今天凌晨,OpenAI CEO Sam Altman 发了一个有趣帖子,大意是:由于最近几轮 GPT-4o 的更新,导致其个性变得过于阿谀奉承,因此官方决定尽快进行修复。
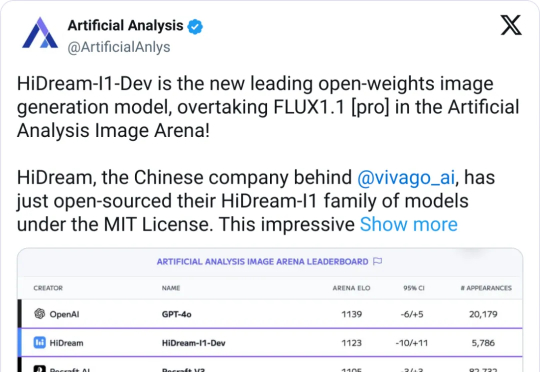
刚出道的 HiDream-I1,拿下了 Hugging Face 趋势榜第二(图像榜第一),Artificial Analysis 文生图第二,排在Midjourney、Google Imagen、FLUX、SDXL 之前,仅次于 GPT-4o 。
从 ChatGPT 引发认知革命到 GPT-4o 实现多模态跨越,AI 技术的每次跃迁都在印证一个底层逻辑 —— 数据质量决定智能高度。而今,这场 AI 浪潮正在反哺数据库领域,推动其从幕后走向台前,完成智能时代的华丽转身。

最近几天,OpenAI 革新的 GPT-4o 图像功能给大家带来了不少乐趣,各路社交媒体都被「吉卜力」风格的图像、视频刷了屏。机器之心还尝试了制作了《甄嬛传》的名场面(视频如下,制作方法参见《GPT-4o 整活!3 个小时、6 个镜头重现吉卜力版《甄嬛传》名场面》)。
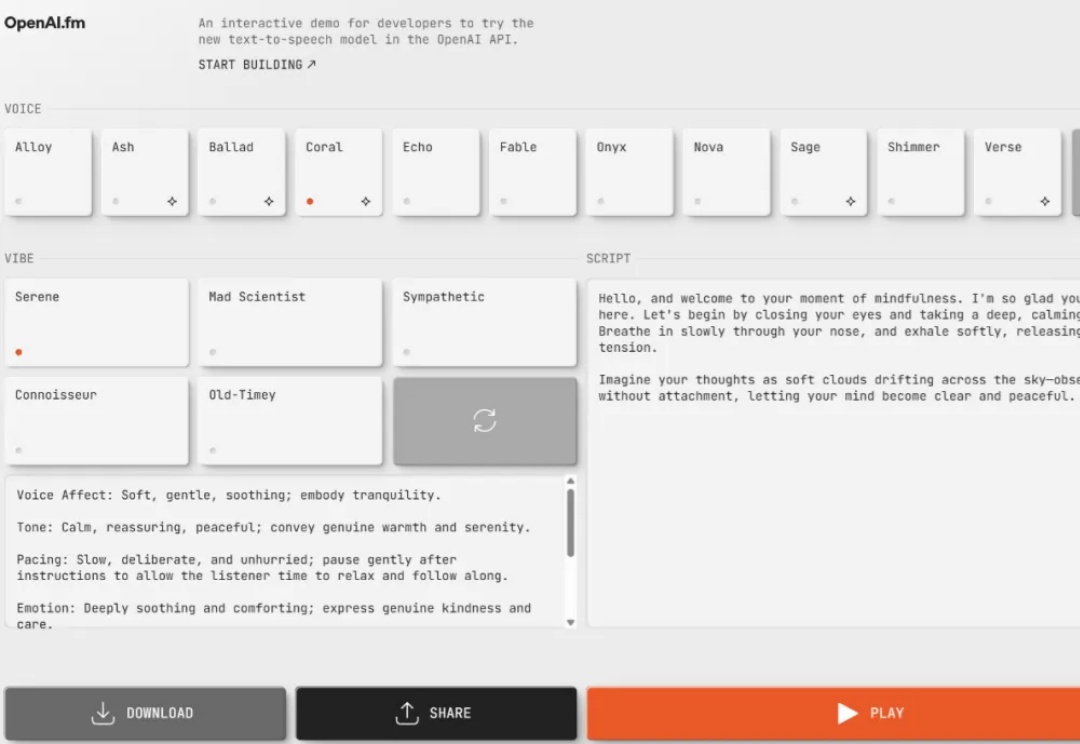
现在,你可以指导 GPT-4o 的说话方式了。
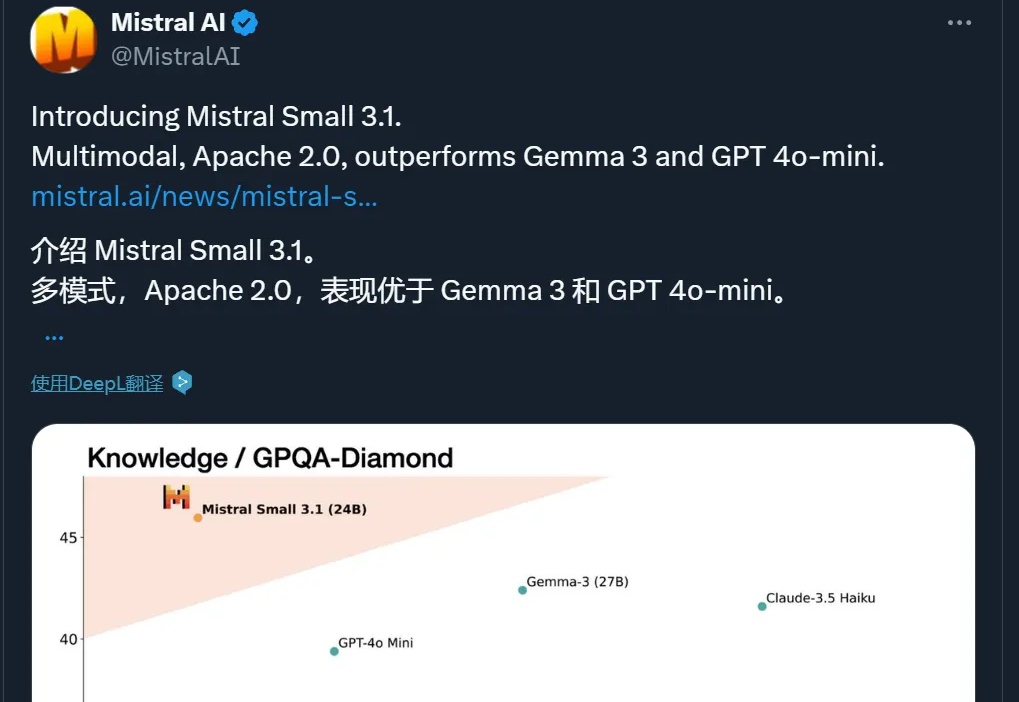
多模态,性能超 GPT-4o Mini、Gemma 3,还能在单个 RTX 4090 上运行,这个小模型值得一试。

要知道,过去几年,各种通用评测逐渐同质化,越来越难以评估模型真实能力。GPQA、MMLU-pro、MMLU等流行基准,各家模型出街时人手一份,但局限性也开始暴露,比如覆盖范围狭窄(通常不足 50 个学科),不含长尾知识;缺乏足够挑战性和区分度,比如 GPT-4o 在 MMLU-Pro 上准确率飙到 92.3%。

Sam Altman 又当了一回谜语人。2 月 16 日,他宣布更新了我们的老朋友 GPT-4o,却没说细节。
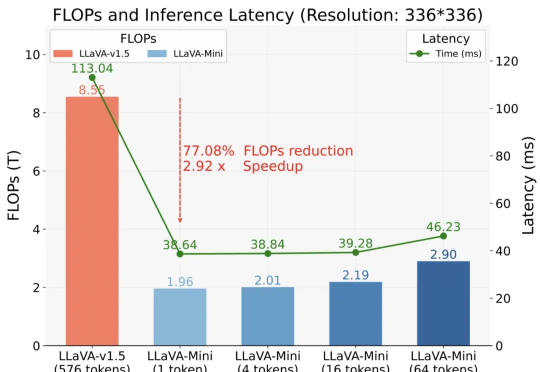
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。